
Rekenen met taal#
Taal#
🌍 ideeën, meningen
👄 natuurlijke taal, woorden, zinnen
🐍 strings (Python)
💻 getallen, bits (computer)
Van strings naat bits#
Van 🐍 strings naar 💻 bits gaan we straks naar kijken
Van strings naar natuurlijk taal#
Van 🐍 strings naar 👄 natuurlijke taal
kan je bepalen hoe “Nederlandstalig” een string is?
Natural language processing (NLP)
We gaan straks zien hoe we rekenkundig Nederlandstaligheid kunnen bepalen.
En verder#
Van 🐍 strings naar 👄 natuurlijke taal en 🌍 grote ideeën
Openstaande vragen in kunstmatige intelligentie (AI)
Als we taal rekenkundig kunnen benaderen, wat zijn dan de mogelijkheden? Hiermee komen we op het gebied van bijvoorbeeld kunstmatige intelligentie (AI).
GPT-3 is een voolbeeld van een kunstmatige intelligentie. Het volledig door AI geschreven artikel kan je vinden in The Guardian. Andere GPT-3 voorbeelden kan je zien op https://gpt3examples.com/.
Caesarcijfer#

Het Caesarcijfer is vernoemd naar de Romein Julius Caesar. Hij gebruikte een versleuteling van berichten op basis van een rotatie van karakters. De sleutel is het aantal stappen van de rotatie.
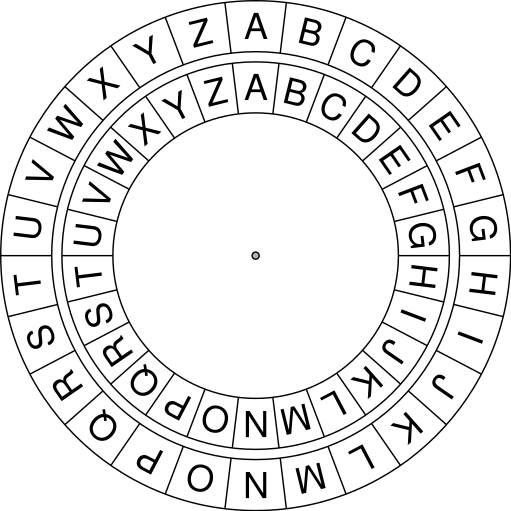
Stel jezelf een dubbele schijf voor met de alle karakters van het alfabet waarbij de middelste schijf kan draaien (roteren).
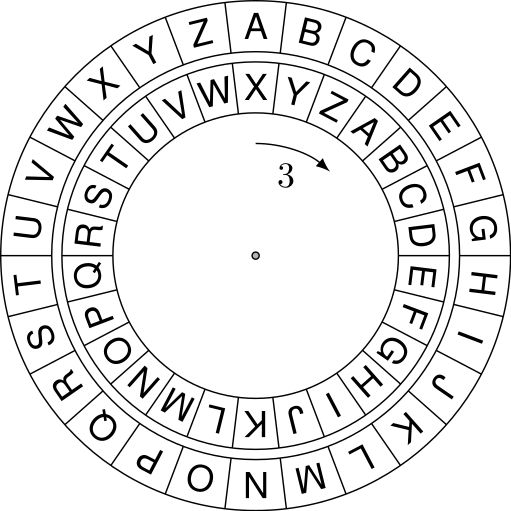
De verzender kiest een rotatie van 3 en elk karakter is nu 3 posities met de klok mee verschoven. Je ziet bijvoorbeeld dat het oorspronkelijke karakter “A” nu gelijk staat aan “D”.
Wat zijn de karakters in het bericht “HOI” na een rotatie van 3?
KRL
De ontvanger van het versleuteld bericht “KRL” heeft dezelfde startpositie. De sleutel (rotatie) is bekend want deze is met de verzender afgesproken.
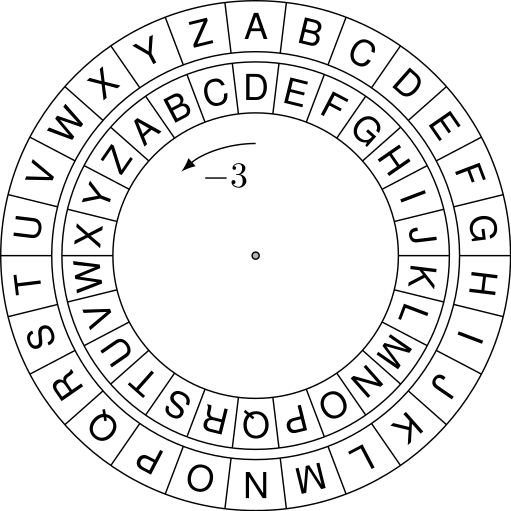
Hoe kan de ontvanger het bericht nu ontcijferen? Door de rotatie in de omgekeerde richting toe te passen (tegen de klok in)! Kan je het versleuteld bericht “KRL” op basis van deze omgekeerde rotatie ontcijferen?
encipher#
Versleutelen
def encipher(s, n):
...
Verschuif elk alfabetisch karakter in string s met n plaatsen in het alfabet
encipher("I <3 Latijn", 0) == "I <3 Latijn"
encipher("I <3 Latijn", 1) == "J <3 Mbujko"
encipher("I <3 Latijn", 2) == "K <3 Ncvklp"
encipher("I <3 Latijn", 3) == "L <3 Odwlmq"
encipher("I <3 Latijn", 4) == "M <3 Pexmnr"
encipher("I <3 Latijn", 5) == "N <3 Qfynos"
# ...
encipher("I <3 Latijn", 25) == "H <3 Kzshim"
Met alfabetisch karakters bedoelen we “a” tot en met “z” in hoofd- of kleine letters.
In [1]: encipher("Bzdrzqbhiedq? Hj gda khdudq Bzdrzqrzkzcd.", 25)
Out[1]: 'Aycqypaghdcp? Gi fcz jgctcp Aycqypqyjybc.'
In [2]: encipher("Bzdrzqbhiedq? Hj gda khdudq Bzdrzqrzkzcd.", 15)
Out[2]: 'Qosgofqwxtsf? Wy vsp zwsjsf Qosgofgozors.'
In [3]: encipher("Bzdrzqbhiedq? Hj gda khdudq Bzdrzqrzkzcd.", 4)
Out[3]: 'Fdhvduflmihu? Ln khe olhyhu Fdhvduvdodgh.'
In [4]: encipher("Bzdrzqbhiedq? Hj gda khdudq Bzdrzqrzkzcd.", 1)
Out[4]: 'Caesarcijfer? Ik heb liever Caesarsalade.'
decipher#
Ontijferen
def decipher(s):
...
Ontcijfer een bericht zonder de rotatie te kennen! Wat zou een goede strategie zijn om dit probleem op te lossen? Een mogelijke strategie is om de kijken nar letterfrequenties, hoe vaak worden karakters in een taal gebruikt en hoe waarschijnlijk is het dat ze in een bepaalde combinatie worden gebruikt.
Nederlands
In [5]: decipher("Bzdrzqbhiedq? Hj gda khdudq Bzdrzqrzkzcd.")
Out[5]: 'Caesarcijfer? Ik heb liever Caesarsalade.'
In [6]: decipher("Aadxas ue exqotfe pq haadflqffuzs hmz baxufuqw yqf mzpqdq yuppqxqz.")
Out[6]: 'Oorlog is slechts de voortzetting van politiek met andere middelen.'
Latijn
In [7]: decipher("Gv vw, Dtwvg?")
Out[7]: 'Od de, Lbedo?'
Een Nederlandse frequentieverdeling is niet gelijk aan Latijn. Wat we hier hadden willen zien was “Et tu Brute?”, Caesar’s beroemde laatste woorden.
Maar dan nog zou het de vraag zijn of het kon worden gevonden, de tekst is wellicht ook te kort.
Denk terug aan de “dozen” die we hebben gebruikt om een voorstelling te maken van wat zich in het geheugen van een computer afspeelt en met wat we nu weten kunnen we dit beeld gaan aanpassen. De “inhoud” van een doos zijn de bits, zoveel is nu wel duidelijk. De inhoud van verschillende dozen kan hetzelfde zijn maar het type bepaalt de representatie, bijvoorbeeld of het integer met waarde 67 of een string met waarde “C” is.
De naam van een waarde (variabele) maakt dus ook niet uit, je weet inmiddels dat je (bijna) elke naam voor een variabele mag kiezen en het is niets meer dan een verwijzing naar de waarde die voor jou betekenis heeft (en je zult misschien hebben gemerkt dat het kiezen van een betekenisvolle naam niet altijd eenvoudig is!).
Beperkingen#
ASCII 8 bits betekent maximaal 256 mogelijke karakters
Maar de 🌍 is groter dan 256 karakters,ñïㅌtwååя?
Historisch gezien was de byte het aantal bits dat werd gebruikt om een enkel karakter van de tekst in een computer te coderen. Het was begin jaren 60 van de vorige eeuw dat dit werd bepaald en dit zie je in ASCII terug, het is een oude tekenset!
ASCII ⊂ Unicode#
Een moderne encodering met ASCII als subset
Tegenwoording wordt van andere tekensets gebruik gemaakt. Unicode is een moderne variant die ASCII als subset heeft. Dit betekent dat 67 nog steeds naar C verwijst, maar 128077 naar 👍. Unicode gebruikt een byte op een veel slimmere manier om optimaal van de mogelijke adresruimte gebruik te maken. De meest gebruikte variant is tegenwoordig UTF-8 hoewel ook UTF-16 en UTF-32 bestaan (16 en 32 bits).
chr en ord#
Zet een getal om naar een karakter
chr(67)
'C'
Zet een karakter om naar een getal
ord("C")
67
Vergelijken#
ord("w")
119
ord("e")
101
"w" > "e"
True
Weet je nog dat Python een mening had? Het is om deze reden dat werk > eten!
decipher#
Een bericht ontcijferen zonder bekende rotatie
In [10]: decipher("Bzdrzqbhiedq? Hj gda khdudq Bzdrzqrzkzcd.")
Out[10]: 'Caesarcijfer? Ik heb liever Caesarsalade.'
Welke strategie, welk algoritme?
Encryptie wordt overal toegepast, of het nu gaat om het beschermen van jouw betaalgegevens of om meeluisteren met een chat of gesprek onmogelijk te maken. Toch hoor je vaak over versleutelingen die “gekraakt” zijn. Hoe zou je een substitutieversleuteling als een Caesarcijfer kunnen breken? Wat zouden geschikte benaderingen (strategie) en bijbehorende handelingen (algoritme) kunnen zijn om dit probleem op te lossen?
Een bericht#
decipher("jgddcp qnnc xqicnc")
We hebben een versleuteld bericht uit het verleden ontvangen maar helaas is de sleutel (de rotatie) niet bekend … hoe zou je dit bericht geautomatiseerd kunnen ontcijferen? We hebben weinig informatie, laten we aannemen dat het bericht in het Nederlands is opgesteld…
Taalherkenning#
Welke rotatie is het meest Nederlandstalig?
rotatie |
|
|---|---|
1 |
|
2 |
|
3 |
|
4 |
|
5 |
|
6 |
|
7 |
|
8 |
|
9 |
|
10 |
|
11 |
|
12 |
|
13 |
|
14 |
|
15 |
|
16 |
|
17 |
|
18 |
|
19 |
|
20 |
|
21 |
|
22 |
|
23 |
|
24 |
|
25 |
|
26 |
|
Voor het versleutelde bericht kan je elke rotatie toepassen zodat je tot een lijst van 26 mogelijke ontcijferingen komt. Maar welk element van deze lijst is het meest … Nederlandstalig?
Nederlandstaligheid meten#
Hoog
Denkend aan Holland zie ik breede rivieren traag door oneindig laagland gaan.
Je zal hier de eerste strophe van het gedicht “Herinnering aan Holland” van Hendrik Marsman herkennen. Dit is een voorbeeld van hoge Nederlandtaligheid wat betreft syntax en betekenis (semantiek).
Middel
De gostak is die welke de doshes distims
Je zal nog steeds “Nederlands” herkennen, maar heeft het betekenis?
Laag
Epadxo, nojarpn, gdxokpw
Dit lijkt op het bericht dat we hebben ontvangen en heeft niet veel met Nederlands te maken!
Voor elke mogelijke rotatie van het versleuteld bericht zal je een maat moeten hebben om te bepalen welke de max is, oftwel wat de meest Nederlandstalige ontcijfering is.
Aantal klinkers#
Is dit een mogelijke maat?
klinkers |
||
|---|---|---|
2 |
|
|
2 |
|
|
5 |
|
|
1 |
|
|
2 |
|
|
2 |
|
|
3 |
|
|
0 |
|
|
4 |
|
|
3 |
|
|
3 |
|
|
0 |
|
|
2 |
|
|
1 |
|
|
4 |
|
|
2 |
|
|
4 |
|
|
1 |
|
|
1 |
|
|
0 |
|
|
7 |
|
|
2 |
|
|
2 |
|
|
1 |
|
|
6 |
|
|
0 |
|
Een mogelijke strategie zou het tellen van het aantal klinkers voor elke rotatie kunnen zijn. Dit is misschien een intuïtief ingegeven strategie, het gebruik van klinkers is immers een kenmerk van een taal. In dit geval hebben we een max gevonden maar hoe Nederlandstalig is deze max? Is dit het oorspronkelijke bericht?
Je kan je afvragen in hoeverre dit een goede maat is. Bijvoorbeeld, aaaa eeeee iii zou een absolute max zijn, maar is het ook betenisvol? Waarschijnlijk niet en daarmee is het een niet heel betrouwbare maat en zullen we op zoek moeten naar iets beters.
Letterfrequentie#
Het vaak worden klinkers én medeklinkers in een taal gebruikt?
Talen verschillen van elkaar en wat is nu één van de kenmerken waar zij zich van elkaar onderscheiden? Syntax! Dit uit zich in het gebruik van klinkers en medeklinkers waar karakters in de ene taal vaker zullen worden gebruikt dan in een andere taal.
Kansen#
De frequentieverdeling van karakters: wat is de kans dat de letter G wordt gebruikt?
Nederlands: 3.17%
Engels: 1.92%
Frans: 0.97%
(G als hoofd- of kleine letter)
Stel dat je een pagina van NOS, BBC of FRANCE.TV op scherm hebt en je zou met de ogen dicht een punt op de pagina aanwijzen, wat is de kans dat je een “a”, “i” of “g” aanwijst? Deze kans zal verschillen omdat het gebruik van klinkers en medeklinkers per taal verschilt.
Deze letterfrequenties zijn bekend op basis van tellingen van héél veel teksten per taal. Een frequentieverdeling van karakters voor Nederlands kan je bijvoorbeeld vinden op WordCreator.
Het vakgebied dat zich onder andere met deze maten bezig houdt is computational linguistics (computationele taalkunde). Dit is een interdisciplinair vakgebied waar de computationele modellering van taalkundige verschijnselen centraal staat.
Opeenvolging#
De kans dat de letter A wordt gebruikt is 7.76% (NL)
Wat is de kans dat G (3.17%) wordt opgevolgd door A?
score |
||
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Deze notatie van getallen zal je misschien vaker zien. Voor decimale getallen zal Python vaak de wetenschappelijke notatie gebruiken om de precicie aan te duiden. In dit geval staat 6.3e-15 gelijk aan \(6.3\cdot{10}^{-15}\).
Het max bericht#
Alea iacta est
–Julius Caesar
Alea iacta est of “de teerling is geworpen” is een uitspraak van Julius Caesar. Het is blijkbaar Nederlandstalig genoeg voor onze strategie! Voor Nedelandstalige teksten zal het preciezer werken en merk daarbij op dat de lengte van een bericht ook van belang is.
Strategie en algoritme#
Strategie
Letterfrequentie is een goede maat voor Nederlandstaligheid
Algoritme
doorloop elke rotatie
bepaal op basis van letterfrequenties de kans op de lettercombinatie per rotatie
vind de
maxkans van alle rotaties